Your a lazy devops, you want to deploy your application in one click BUT you don’t want Nagios to send alerts while you’re deploying. Solution: disable Nagios notifications while deploying.
This article will help you organize, clarify and reduce the size of your cucumber scenarios.
1. Organize your garden
Keep your feature files organized by grouping them by business object, then action and context if any. I put all the feature files in the same directory. For instance:
The steps specific to the application should be organized by business object as well (bank_account_steps.rb, user_steps.rb…). Keep the file organized grouping the steps by Given / When / Then.
Do not overload the files generated by Cucumber like step_definitions/web_steps.rb and support/env.rb with your own steps, helpers or setup code. These files are likely to get overwritten when you update Cucumber so store your stuff in your own files.
2. Custom steps make your scenario DRY and accessible
Scenarios should have the same lifecyle as your code: Red, Green, Refactor to make them DRY and easy to read.
Group multiple steps together. For instance:
123456
GivenIfollow"Send money"WhenIfillin"Email"with"mukmuk@example.com"AndIfillin"Amount"with"10"AndIselect"Bank account"from"Source"AndIpress"Send"ThenIshouldsee"You've sent $10 to mukmuk@example.com"
Given%{I send "$amount" to "$email" from my "$source"}do|amount,email,source|Given%{I follow "Send money"}When%{I fill in "Email" with "#{email}"}And%{I fill in "Amount" with "#{amount.delete('$')}"}And%{I select "#{source}" from "Source"}And%{I press "Send"}Then%{I should see "You've sent $#{amount} to #{email}"}end
This step can then be easily reused in other scenario keeping your features DRY. It also decouples the scenario from the UI so that you won’t have to change dozens of feature files when the UX guru changes translations or user flows.
3. Background: setup the DRY way
Make the feature focus on one business object/action/context and the background will get longer than the scenarios.
12345678910111213
Feature: A user can cancel a transaction unless it's claimed by the recipientBackground: Given I am logged inAnd I send "$10" to "mukmuk@example.com" from my "Bank account"Scenario: I can cancel as long as the payment is not claimed When I cancel my latest transactionThen I should see a cancellation confirmationScenario: I can't cancel once the payment is claimed Given "Mukmuk" claimed the latest transactionThen I can't cancel my latest transaction
4. Scenario outlines: scenario with variables!
A scenario outline contains variables allowing you to test multiple context using a truth table. For instance I use them to make sure that validation errors are displayed properly:
1234567891011
Scenario Outline: Add invalid bank account displays inline errors Given I follow "Add Bank Account"When I fill in "<field>" with "<value>"And I press "Add Bank Account"And I should see the inline error "<error>" for "<field>"Examples: | field | value | error | | Account | | Can't be blank | | Account | Sixty five | Should be 1 to 12 digits | | Account | 1234567890123 | Should be 1 to 12 digits |
5. Multi-line step arguments: give your step a table for lunch!
A step can take a multi-line table as an argument. This is a great way to load up a bunch of data or to test the rendering of lists and tables. For instance:
123456
Given I sent "$25" to "mukmuk@example.com" from my "Bank account"Then I should see the following transaction history: | create | complete | | deposit | in_progress | | transfer | pending | | withdrawal | pending |
The step definition looks like the following:
12345
Then "I should see the following transaction history:" do |table| table.raw.each do |event, state| page.should have_css("tr.#{event}.#{state}") end end
I hope that these tips will help you growing healthy cucumber features!
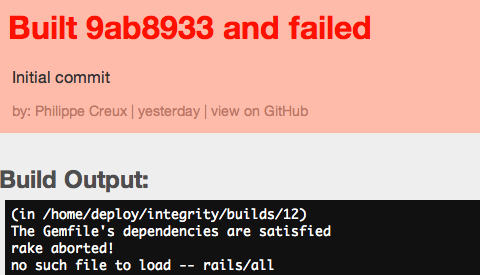
The latest “stable” version of Integrity (v22) doesn’t play well with Rails 3 (or any other application using bundler 1.0). Basically the Integrity’s Gemfile is used in place of the application’s Gemfile when running the tests.
You also need to force your Rails application to use its Gemfile. To do so, update the file /config/boot.rb with the following:
123456789
require'rubygems'# Set up gems listed in the Gemfile.GEMFILE_PATH=File.expand_path('../../Gemfile',__FILE__)ifFile.exist?(GEMFILE_PATH)# Force the rails 3 application to use its GemfileENV['BUNDLE_GEMFILE']=GEMFILE_PATHrequire'bundler'Bundler.setupend
I enjoy using the let() method as it makes my specs easier to read and maintain than setting up instance variables in before(:each) blocks. The let() method can be used like this:
My main concern was that the block gets evaluated everytime the method is called. In the example above, Factory(:account) will run and create a new record for every single spec.
To increase our specs performances let’s refactor this and setup the account in a before(:all) block.
The account is now setup once before the specs get run. Each spec will be run in a separate transaction to prevent side effects. The account will be rolled back to its initial state before each spec then. Since ActiveRecord is not aware of the rollback we reload the account object from the database every time it’s called.
Specs are now faster but I want them to be as pretty as they were. Let’s make a little helper called set().
The records created by set() will remain in your database. You can use DatabaseCleaner with the :truncation strategy to clean up your database. So far in RSpec 2.0, before(:all) runs before all describe/context/it while after(:all) runs after every single describe/context/it. Just make sure that you call DatabaseCleaner.clean in a before(:all) or after(:suite) blocks then. :)
I hope you’ll enjoy using this little helper. It’s very young and it has been tested with RSpec 2 only, so fill free to fill up the comments with enhancements and bug reports!
EngineYard’s chef recipe for DelayedJob requires script/runner. To use this recipe with Rails 3 I’ve just made script/runner for Rails 3. Here is the code:
After a year using RSpec, I’m happy to share “(My) RSpec Best Practices and Tips”. Let’s make your specs easier to maintain, less verbose, more structured and covering more cases!
Use shortcuts specify {}, it {} and subject {}
You think RSpec is verbose? In case your code doesn’t need any description, use a specify block!
123
it"should be valid"do@user.shouldbe_validend
can be replaced with
1
specify{@user.shouldbe_valid}
RSpec will generate a nice description text for you when running this expectation. Even better, you can use the it block!
Start your contexts with when and get nice messages like:
1
Userwhennonconfirmedwhen#confirm_email with wrong token should not be valid
Use RSpec matchers to get meaningful messages
In case of failure
1
specify{user.valid?.should==true}
displays:
123
'User should == true'FAILEDexpected:true,got:false(using==)
While
1
specify{user.shouldbe_valid}
displays:
12
'User should be valid'FAILEDexpectedvalid?toreturntrue,gotfalse
Nice eh?
Only one expectation per it block
I often see specs where it blocks contain several expectations. This makes your tests harder to read and maintain.
So instead of that…
12345678
describeDemoMandoit"should have expected attributes"dodemo_man=DemoMan.newdemo_man.shouldrespond_to:namedemo_man.shouldrespond_to:genderdemo_man.shouldrespond_to:ageendend
Big specs can be a joy to play with as long as they are ordered and DRY. Use nested describe and context blocks as much as you can, each level adding its own specificity in the before block.
To check your specs are well organized, run them in ‘nested’ mode (spec spec/my_spec.rb -cf nested).
Using before(:each) in each context and describe blocks will help you set up the environment without repeating yourself. It also enables you to use it {} blocks.
Bad:
1234567891011121314151617181920212223242526
describeUserdoit"should save when name is not empty"doUser.new(:name=>'Alex').save.should==trueendit"should not save when name is empty"doUser.new.save.should==falseendit"should not be valid when name is empty"doUser.new.should_notbe_validendit"should be valid when name is not empty"doUser.new(:name=>'Alex').shouldbe_validendit"should give the user a flower when gender is W"doUser.new(:gender=>'W').present.shouldbe_aFlowerendit"should give the user a iMac when gender is M"doUser.new(:gender=>'M').present.shouldbe_anIMacendend
describeUserdobefore{@user=User.new}subject{@user}context"when name empty"doit{shouldnotbe_valid}specify{@user.save.should==false}endcontext"when name not empty"dobefore{@user.name='Sam'}it{shouldbe_valid}specify{@user.save.should==true}enddescribe:presentdosubject{@user.present}context"when user is a W"dobefore{@user.gender='W'}it{shouldbe_aFlower}endcontext"when user is a M"dobefore{@user.gender='M'}it{shouldbe_anIMac}endendend
Test Valid, Edge and Invalid cases
This is called Boundary value analysis, it’s simple and it will help you to cover the most important cases. Just split-up method’s input or object’s attributes into valid and invalid partitions and test both of them and there boundaries. A method specification might look like that:
12345678910
describe"#month_in_english(month_id)"docontext"when valid"doit"should return 'January' for 1"# lower boundaryit"should return 'March' for 3"it"should return 'December' for 12"# upper boundarycontext"when invalid"doit"should return nil for 0"it"should return nil for 13"endend
I hope this will help you improve your specs. Let me know if I missed anything! :)
If you have a server running the default Ruby interpreter (“Matz’s Ruby Interpreter” or “Ruby MRI”) and you want to switch to Ruby Enterprise Edition (REE) the following script will help you migrating the gems.
Once you have installed Ruby Enterprise Edition run this script so that REE installs the gems installed on your default ruby environment.
You just got a brand new machine but you won’t like to spend hours tuning it to get the same configuration as the one you have used for years?
Let’s transfer your Ubuntu configuration and applications to your new computer in three simple steps.
This method is cross-architecture. I moved successfully my configuration and applications from an Ubuntu 9.04 32bit to a 64bit one.
Prerequisites:
The same version of Ubuntu is installed on both machines. The architecture (32/64 bit) can be different.
Step 1: Store the list of installed packages
Run the following command on the source machine to store the installed packages names in ~/pkglist:
sudo dpkg --get-selections | sed "s/.*deinstall//" | sed "s/install$//g" > ~/pkglist
Step 2: Transfer your config
Use scp or rsync or even a flash drive to transfer your home directory (~/*, ~/.*), the source list (/etc/apt/sources.list) and any other files you customized or installed (like apache config under /etc or softwares on /opt) from the source machine to the target one.
Step 3: Install packages
On the target machine run the following command in a failsafe terminal session to install your packages:
I’ve just posted the code of Jabber-SH on GitHub. Jabber-SH is a ruby hack that allows you to administrate a remote computer via a command line through a Jabber client. It’s like SSH via GoogleTalk! :)
I coded it nine month ago then I planned to add some specs, to store the configuration in a yaml file, to make a gem out of it but… I didn’t and I won’t get a chance to do that. So here are the 25 lines of code… hackish eh?!
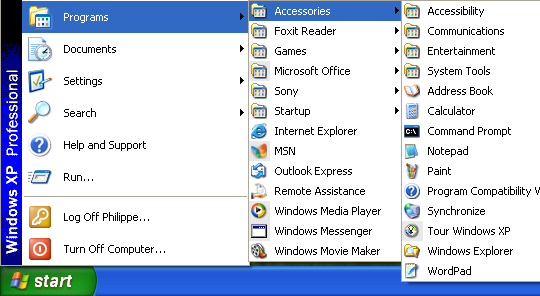
Bottom-up programming starts by developing the data model before designing the user interface. Windows Start/Programs menu illustrates this approach. Since programs shortcuts are stored in the directory Programs the menu displays the content of this directory.
Top-down programming starts by designing the user interface before developing the data model. Mac OS X dock illustrates this approach. As it should be easy for a user to launch an application the dock displays big icons accessible in one click.